
In today’s data-driven economy, managing and analyzing vast amounts of information efficiently is critical for organizations across all industries. As data becomes more complex and voluminous, there would be a limitation to processing and storing the data manually. Hence, three core storage paradigms have emerged to support modern analytics: Data Warehouse, Data Lake, and Data Lakehouse. Understanding their differences, use cases, and adoption patterns is essential for data scientists seeking to build scalable, cost-effective, high-performance systems.
<🏢 Data Warehouse: Structure, Speed, and Consistency>
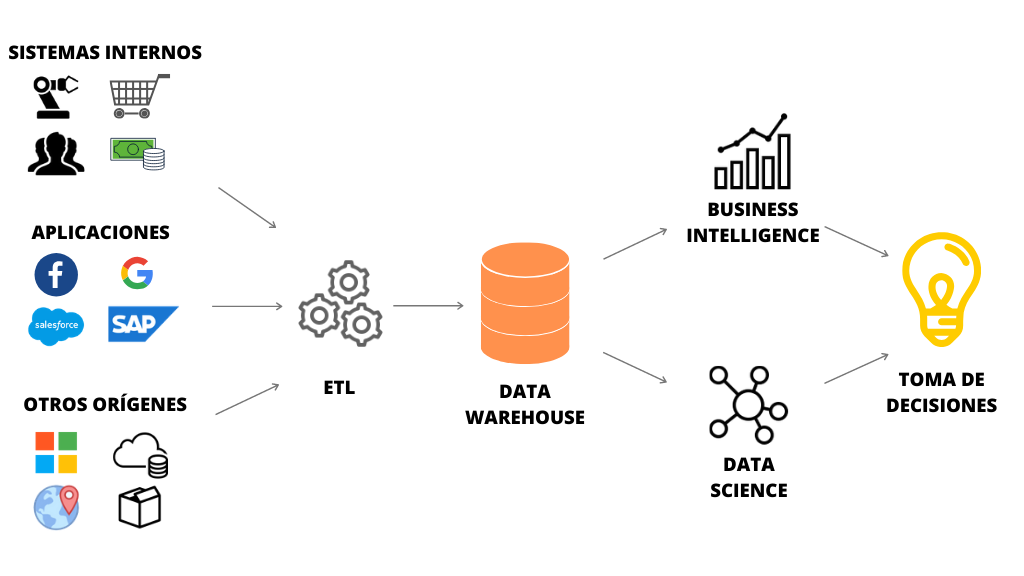
A Data Warehouse is a centralized repository for structured data and analytical workloads. It uses a schema-on-write approach—data must be cleaned, transformed, and formatted before storage. This ensures fast querying and high data quality but reduces flexibility for unstructured or rapidly changing data. Traditional data warehouses, including platforms such as Amazon Redshift, Google BigQuery, and Snowflake, have been widely adopted in the finance, retail, and healthcare sectors. For example, Netflix leverages Amazon Redshift to analyze customer engagement metrics, enabling personalized recommendations and optimized content delivery.
<🌊 Data Lake: Flexibility and Scale for Raw Data>
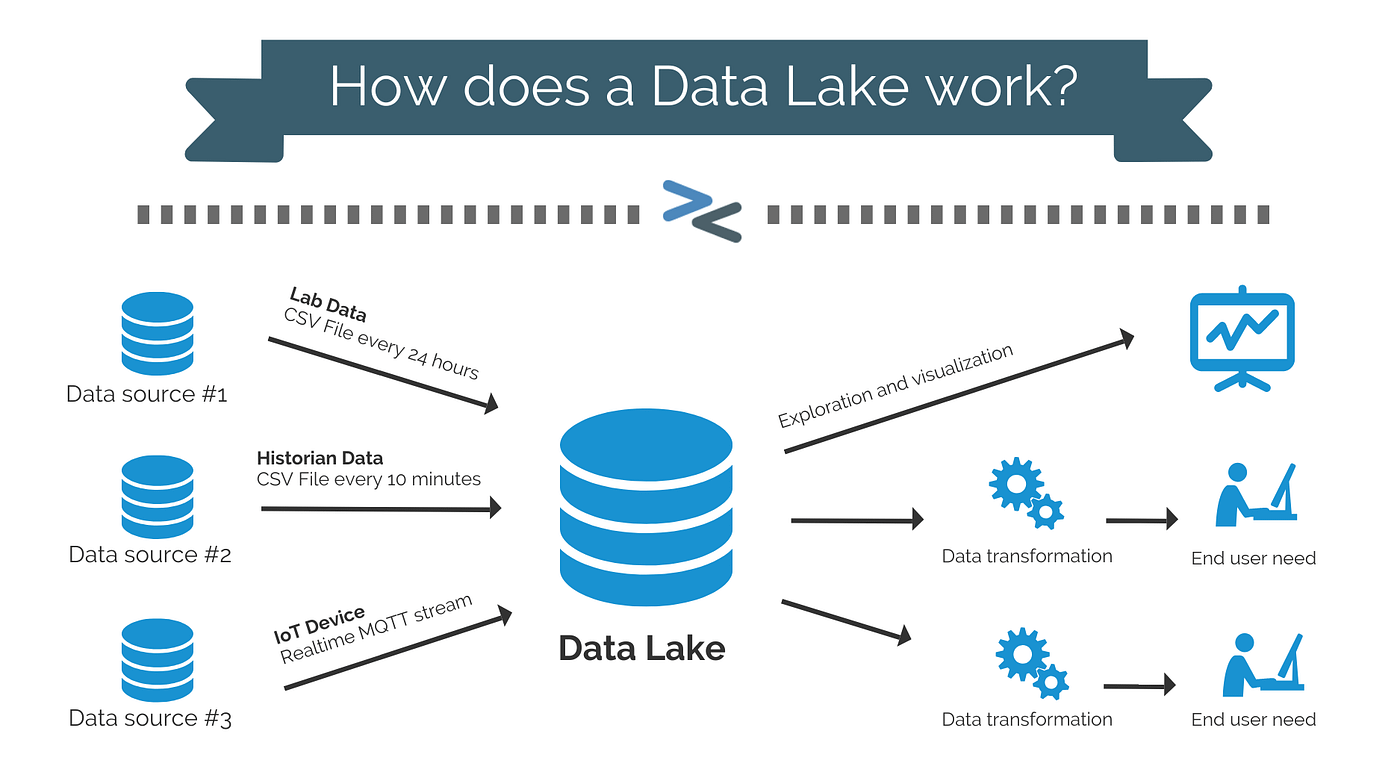
In contrast, a Data Lake is designed to handle vast volumes of raw, semi-structured, unstructured, and structured data. It uses a schema-on-read model—structure is applied only when data is accessed—offering maximum flexibility for diverse and evolving datasets.
Apache Hadoop, Amazon S3, and Azure Data Lake support this paradigm. A prime example is Uber, which uses a Hadoop-based data lake to ingest GPS data, user interactions, and sensor inputs in real-time to power features like dynamic pricing and route optimization.
However, data lakes’ flexibility can introduce problems with data governance, consistency, and performance—often called “data swamp” challenges.
<🔁 Data Lakehouse: A Unified Architecture>
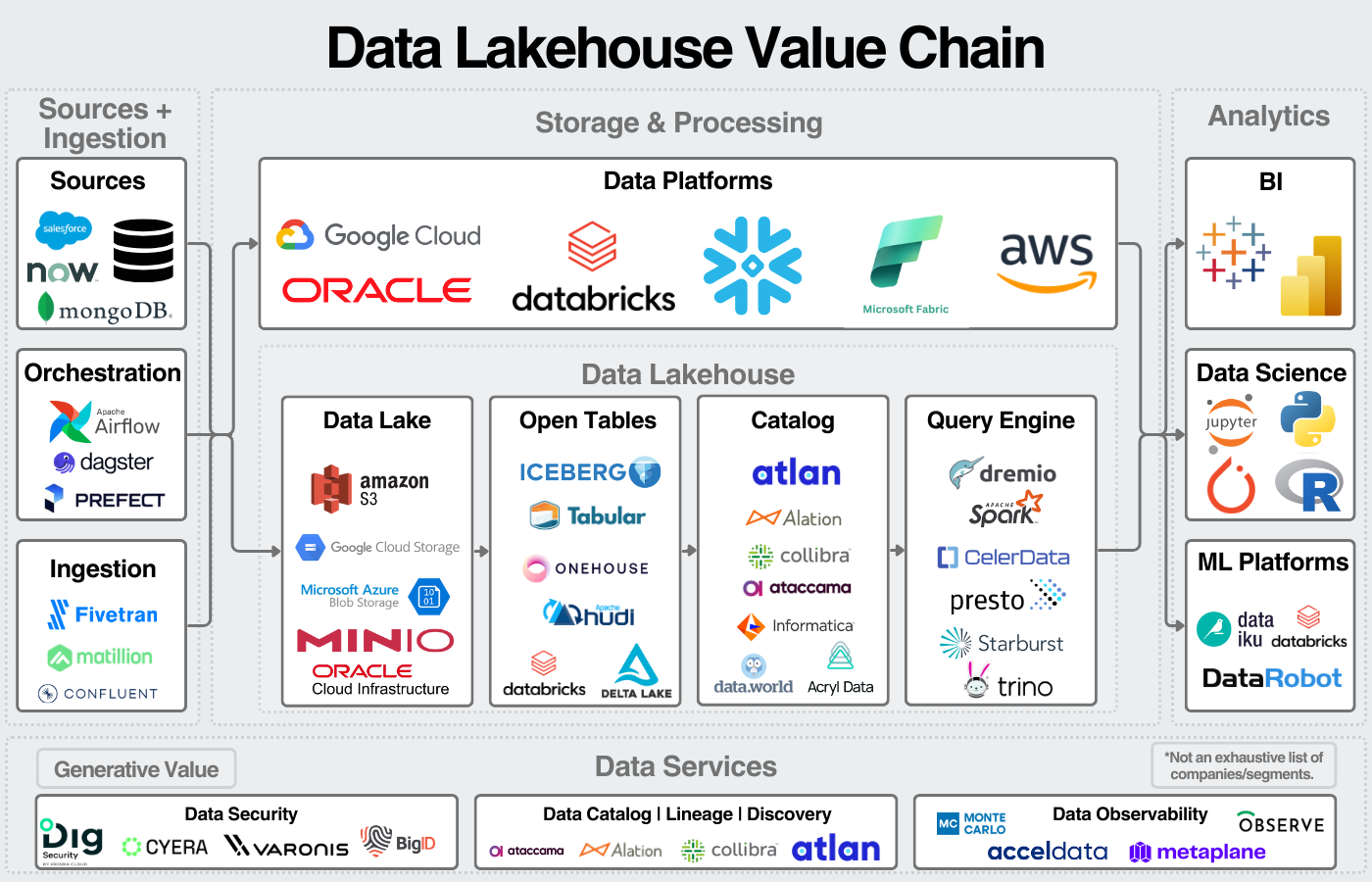
The Data Lakehouse model emerged to bridge the gap between the rigid structure of data warehouses and the flexibility of data lakes. It blends the best of both: the low-cost, scalable storage of a lake with the performance, consistency, and transactional support of a warehouse.
Lakehouses support business intelligence (BI) and machine learning (ML) workloads on a single platform, reducing the need for complex ETL pipelines or duplicated data environments. Key technologies include the Databricks Lakehouse Platform, Delta Lake, and Apache Iceberg. For instance, Adobe uses Databricks Lakehouse to unify customer data for AI-driven marketing analytics, streamlining workflows and reducing infrastructure overhead.
<🧠 Why it’s crucial for Data Scientists>
Knowing how these architectures differ is fundamental for anyone working with data. They dictate how data is stored, accessed, and processed—directly influencing model performance, iteration speed, and overall operational efficiency. With the rapid rise of generative AI, real-time analytics, and hybrid data applications, platforms that can support diverse workloads are becoming essential. This is why the lakehouse model is seeing strong momentum in both startup and enterprise environments.
<🔮 Future Trends and Industry Movement>
Recent trends highlight the shift toward flexible, unified architectures. Microsoft’s enhancements to Azure Synapse now reflect real-time data integration capabilities. The industry also embraces open table formats like Apache Iceberg, designed for large-scale, cloud-native analytics. As the data ecosystem continues to evolve, professionals who understand these foundational architectures will be better equipped to create intelligent systems that are robust, cost-conscious, and aligned with business strategy.
<References>
Flaningam, Eric. “A Primer on the Data Lakehouse.” Public Comps, 28 June 2024, blog.publiccomps.com/a-primer-on-the-data-lakehouse/. Accessed 23 Mar. 2025.
“What Is a Data Lakehouse, and How Does It Work?” Google Cloud, cloud.google.com/discover/what-is-a-data-lakehouse.
Mahendra, Dr. “I Recently Advised a Team of Data Architects to Design and Develop a High-Performance Data Science Platform While Effectively Complying with Data Governance and Privacy Compliance (E.g.” Linkedin.com, 23 Feb. 2023, www.linkedin.com/pulse/lakehouse-convergence-data-warehousing-science-dr-mahendra/.
Leave a Reply