Machine Learnings are utilized when there’s a large amounts of data that needs to be processed and analyzed for particular usage, to analyze various patterns, make predictions based on the training data. In real life, we use machine learning across different sectors of industries, such as retails, E-commerce, education, entertainment to manufacturing. Moreover, it also could be used in the field of security and surveilance. To start off, we gotta know the brief process of machine learning model. Firstly, we chose the case of interest and construct machine learning algorithm that could be later on used as predictive model. The process of deploying typical model development could vary based on the attributes of dataset and the correlated stakeholders related to the predictive model.
<Types of Machine Learning Algorithm>
- – Supervised v. Unsupervised algorithm
- When it comes to machine learning algorithm, there are two big types-supervised and unsupervised algorithm.
- Supervised learning is when algirithm learns from labled data, where input-output pairs are provided. Its main goal is to predict for new inputs. So the classification(categorical labels) examples are K-Nearest Neighbors(KNN),Decision trees and random forest- for email spam detection,image recognition(assign datapoints to predefined categories) . For regression, there are linear regression,Ridge/Lasso regression and polynomial regression-predict house prices, stock market trends(predict continous numerical values).
- Unsupervised learning is when algorim learns patters from unlabled data which means to discover the pattern or structures of the datasets. The examples would be K-Mean,Hierarchical clustrings-customer segmentation, anomaly detection(group similar items without predifined labels).
<Model Evaluation- Confusion Matrix> : Why do we need it?
Conducting evaluation is used to ensure that model generalizes well to unseen data(test data) rather than only training data that has been used to train the predictive model. Model evaluation prevents from overfitting and make sure that quality of predictive model is accurate enough to be adapted to the dataset that needs to be analysed. First, we split the data into training set and test set. Then, we use various performance metrics depending on classification and regression model.
- <1.1 Accuracy>
- -Refers to the percentage of data that is accurately classified as 0 to 0 and 1 to 1 through the classification model. It is difficult to use as an evaluation scale for an unbalanced data set.
- ex) binary classification(spam detection), fraud detection
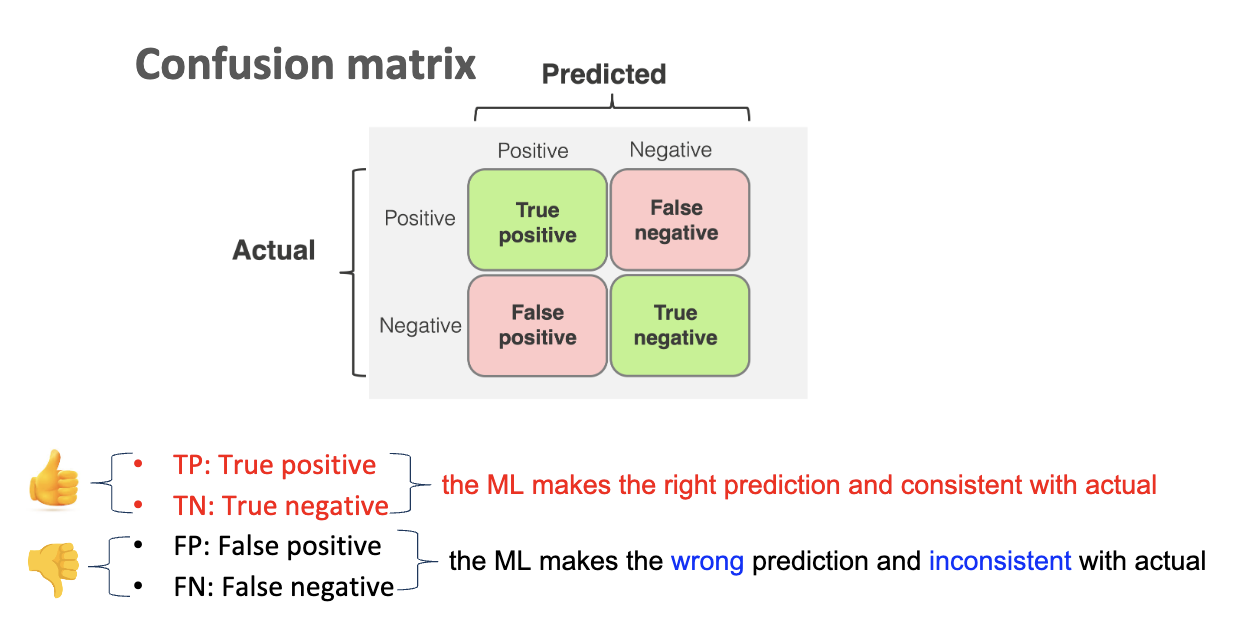
- <1.2 Precision>
- -Measures the accuracy of positive predictions.
- ex) the google search:
- • In Google search, false positives (irrelevant search results) degrade the user experience. Users expect to see results that are highly relevant to their query at the top of the search page. High precision ensures that most of the returned results are relevant, providing a better and more efficient user experience.
- <1.3 Recall>
- – Measures the ability of a model to correctly identify all relevant cases (true positives)
- ex) When treating the cancer patients:
- • In cancer treatment, false negatives are critical errors. A false negative means the system fails to identify a patient with cancer, potentially leading to untreated conditions that can worsen and become fatal. Prioritizing high recall ensures that most (if not all) patients with cancer are flagged for further investigation or treatment, even if it means accepting some false positives.
Leave a Reply